研究の一環でext3ファイルシステムのファイル管理方法や、ファイルを削除した時の復元について色々調べたので、それを忘れないように記事にしておこうと思います。
はじめに
今回はext3ファイルシステムについて調査してみました。僕はLinuxでファイルを扱う前提の研究をしているし、大規模環境でのファイルの処理はとても重要だと思っています。
また、ファイルシステムについて理解を深めておく事で、今後新たなネタにならないか等も考えています。現在はext4やBtrfs等の調査が進んでいますが、改めて基本に戻ってext3について調査しました。
まずは、分かりやすいようにext3ファイルシステムでファイルを削除した場合に、どのようにファイル復元ができるのかを考えながら調べてみました。
ext3ファイルシステムとは
まず、ファイルシステムとはコンピュータのリソースを操作するための機能です。今回対象としたext3と呼ばれるThird extended file systemは、以前はLinuxで主流(今はかなり変わってきている)のファイルシステムで、ext2と互換を保ちつつジャーナリング機能を追加したファイルシステムです。
ここで重要なキーワードとして、ディレクトリエントリ、inode、ジャーナリングを挙げておきます。これらを1つずつ見ていきましょう。
ディレクトリエントリ
まずは、inodeとディレクトリエントリです。まずは下の図(少し分かりにくいですが)を見て下さい。
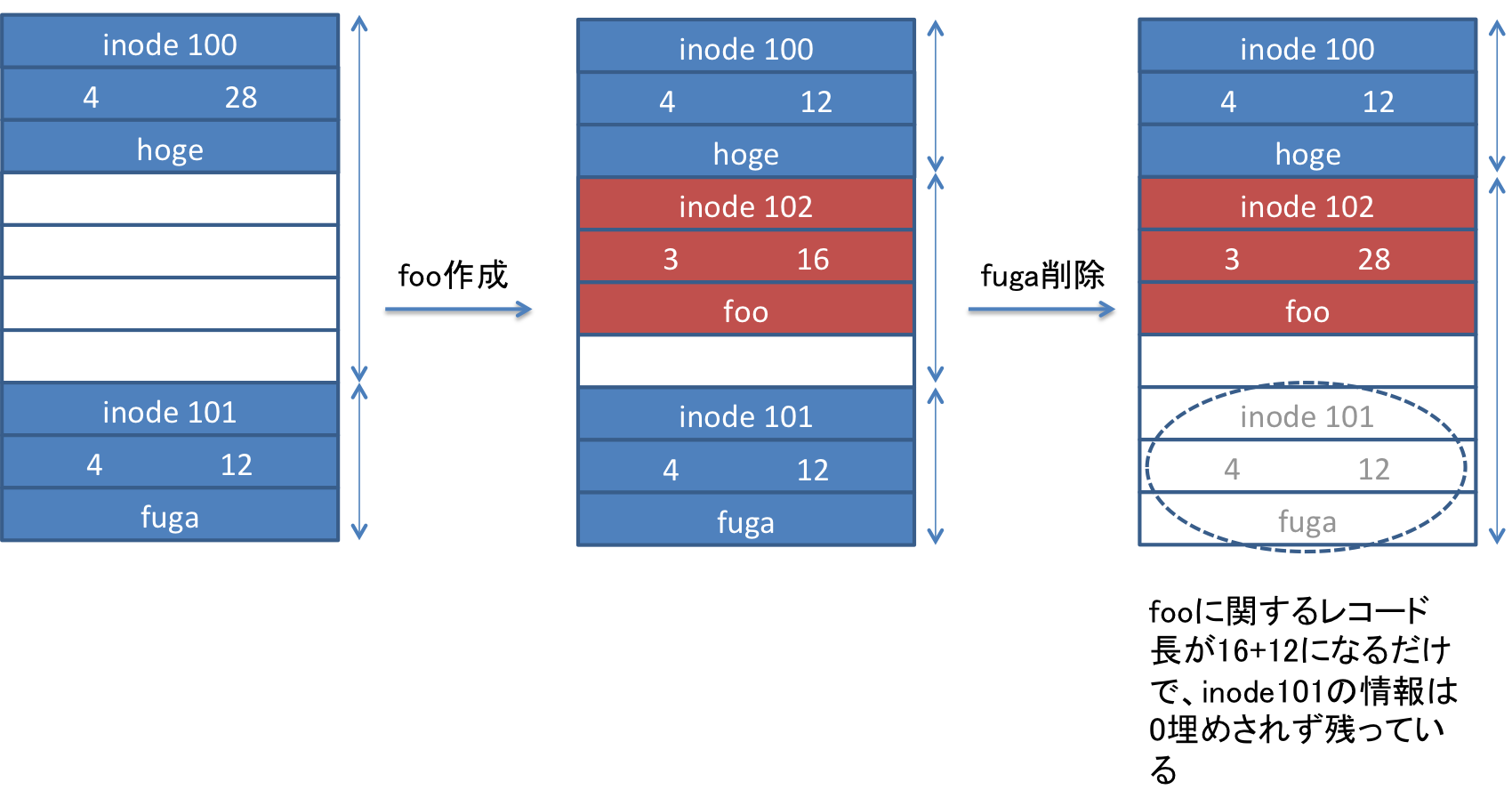
上記のように、まず左から、ファイルhogeとfugaに関するディレクトリエントリがあったとします。この場合、ディレクトリエントリには、それぞれinode番号(100)、ファイル名長(4)、レコード長(28)、ファイル名(hoge)、があると思って下さい。レコード長は基本的には4byteの倍数になります。
このようにディレクトリエントリがあった場合に、同じディレクトリに新たなファイルfooを作成するとします。すると、OSはfooに関するディレクトリエントリを作成できるスペースを探しに行き、ファイルhogeに対するディレクトリエントリはレコード長が28であるが、ファイル名長が4であるため、レコード長は12(この数字は簡単のために例として使っています)で十分だと解釈されます。また、fooに関するディレクトリエントリも28-12の16以下で大丈夫だと判断されます。
その結果、hogeのレコード長が28から12バイトに短縮され、その続きにfooのディレクトリエントリを作成します。作成したディレクトリエントリのレコード長は、使われていない領域も含めて28-12の16バイトとしておきます。
そこからさらに、元々あるファイルfugaを削除するとどうなるのでしょうか。OSはディレクトリエントリを上から辿って行き、該当のディレクトリエントリが不要だった場合は、1つ前のディレクトリエントリであるfooのレコード長を16から16+fugaのレコード長12の28バイトに書き換えます。しかし、これはレコード長を伸ばしただけで、この段階ではfugaのディレクトリエントリは0埋め等はされず、データとして存在する(ディレクトリエントリの探索ルールからは見えない)状態のままになります。
これが、ディレクトリエントリの追加・削除の仕様になります。この仕様を理解しておくことは、削除したファイルを復元する場合に非常に重要になってきます。
inode
続いてinodeについて見ていきましょう。まずは下の図を見て下さい。
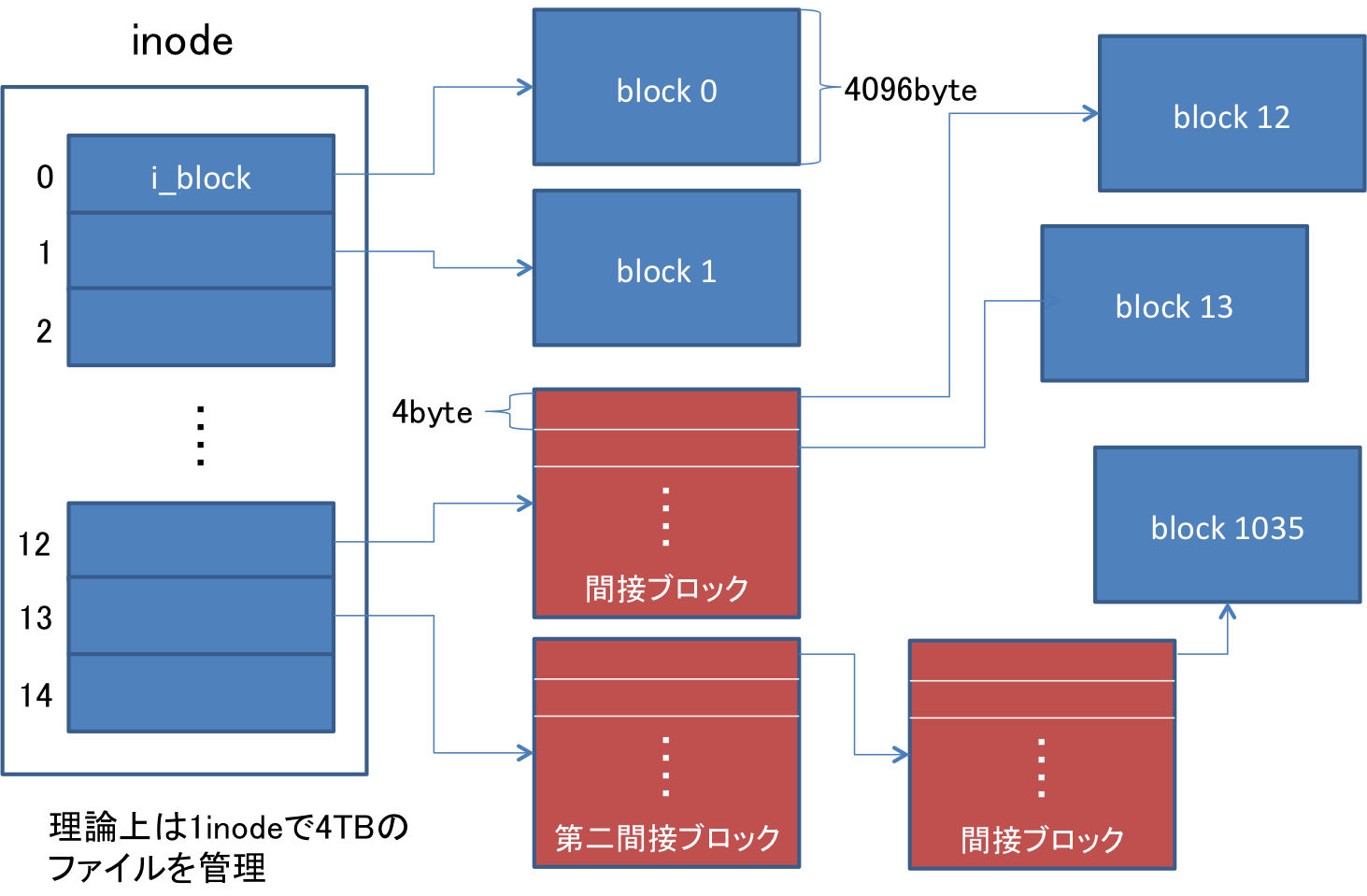
inodeの情報の中には、i_blockと呼ばれるデータが15個格納可能で、0から11テーブルまでには普通にそのinodeが指し示すファイルデータのブロックのアドレスを格納しています。しかし、データブロックは大抵4096byteの場合が多く、普通に15個同じようにデータブロックのアドレスを格納していては15×4096byteのファイルしかinodeで管理できません。
そこで、12から14個目には関節ブロックと呼ばれるブロックのアドレスを指定します。関節ブロックは、ブロックの中にデータブロックのアドレス4byteをブロックサイズ分だけ格納しておくことができます。それによって、データブロックサイズを4096byteにしていた場合は、4096/4の1024個のデータブロックのアドレスを扱えるようになります。
さらに、13番めのi_blockには第2関節ブロックとして、関節ブロックそのもののアドレスを1024個分格納しておけます。14番目のi_blockには第3関節ブロックとして、第2関節ブロックを1024個分格納しておくことができます。
このような仕組みにより、1つのinodeでデータ・ブロックを4096バイトとした場合、理論的には約4TBのファイルを扱う事が可能になります。実際にはこの仕組以外の所でファイルサイズの上限にひっかかってしまいますので、あくまでinodeの観点からは、という所に注意して下さい。
ジャーナリング
次にジャーナリングです。
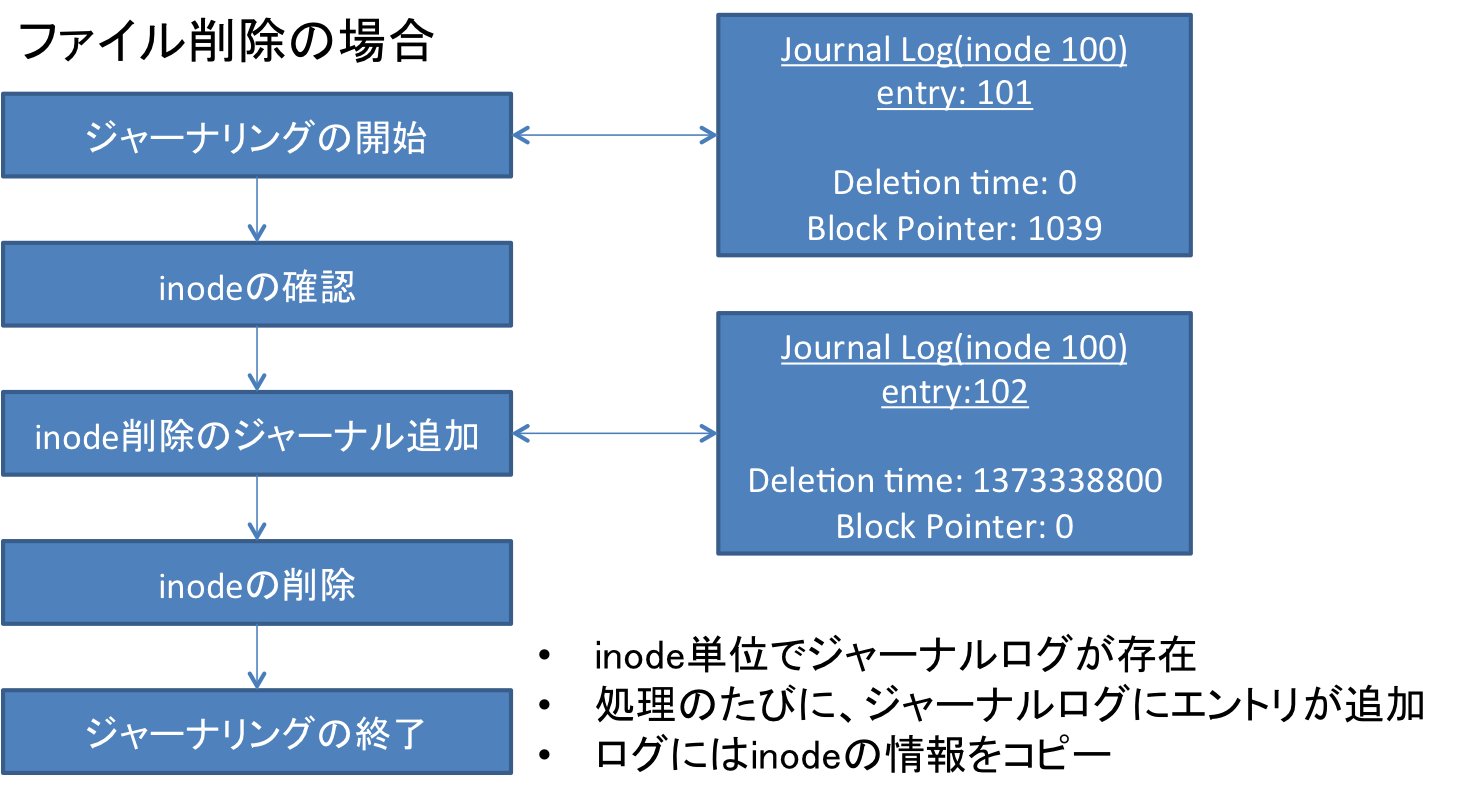
ジャーナリングはext2からext3に追加された機能です。上図のように、例えばファイルを削除する場合について見てみます。
ジャーナルログには、上図のようにinode番号に関する情報と紐づくデータがいくつか存在し、ここでは削除された時間であるDeletion timeとinodeが指すデータブロックのアドレスであるBlock Pointerに注目します。
削除前は、上図のようにファイルが存在するのでDeletion timeは0になっています。また、Block Pointerも存在します。これはinode上の情報とも一致します。ここで、ファイルの削除を行うと、まず、ファイルをこの時間に削除するという意味で、ジャーナルログにも削除した時間をDeletion timeに、Block Pointerに0を与えたるログを追加します。これによって、最新のジャーナルログからは削除したファイルのデータ・ブロックがわからなくなります。
そして、実際に同様にinodeテーブル上のデータブロックのアドレスを0埋めにして、inode情報を削除し、ジャーナリングのトランザクションは終了となります。
この時点でinodeの情報は基本的に追えなくなります。
はたしてext3でファイルの復元は可能か?
上記の、ディレクトリエントリ、inode、ジャーナリングの仕様を元に、ファイルを削除した後にファイルを復元可能かを考えてみます。
まず、ext3の開発者達は以下のように「不可能だ」と述べています。
Q: How can I recover (undelete) deleted files from my ext3 partition?
Actually, you can’t! This is what one of the developers, Andreas Dilger, said about it:
In order to ensure that ext3 can safely resume an unlink after a crash, it actually zeros out the block pointers in the inode, whereas
ext2 just marks these blocks as unused in the block bitmaps and marks the inode as “deleted” and leaves the block pointers alone.Your only hope is to “grep” for parts of your files that have been deleted and hope for the best.
ファイル削除後には、inode上のブロックポインタを0にするため追えないだろうと言っています。確かにその通りで、inode上のデータブロックのアドレスをファイル削除のタイミングで0にするので追えないように思われます。
はたして本当にそうでしょうか?ある条件下ではファイルを復元することができたりしないでしょうか?ということで、本当にできないかを更に考えてみました。
ファイル削除後にWriteが起きない条件下で復元可能では
ファイル削除後に、そのファイルシステム上に新たな書き込みがされない状況においては、ある程度ファイルが復元できるのではないかと考えました。
なぜかというと、inodeの情報は消えていたとしても、ジャーナルログサイズにもよりますが、削除したファイルのinode番号がわかれば、そこからそのinodeに関するジャーナルログを追う事ができ、最新のジャーナルログはBlock Pointerが0になっているはずですが、その「一つ前」のジャーナルログを見てやれば、そこからそのinodeが指すデータブロックのアドレスを得る事できるのではないかと考えました。
さらに、Writeが起きてない前提なので、データブロックのデータは基本的は残っている可能性が高く、後はそのinodeのファイル名を特定すれば、無事ファイルを復元できると考えられます。削除したファイルとinodeの紐付けをどう見つけるかがポイントになるでしょう。
では実際にどうやってやるかを図で追ってみましょう。
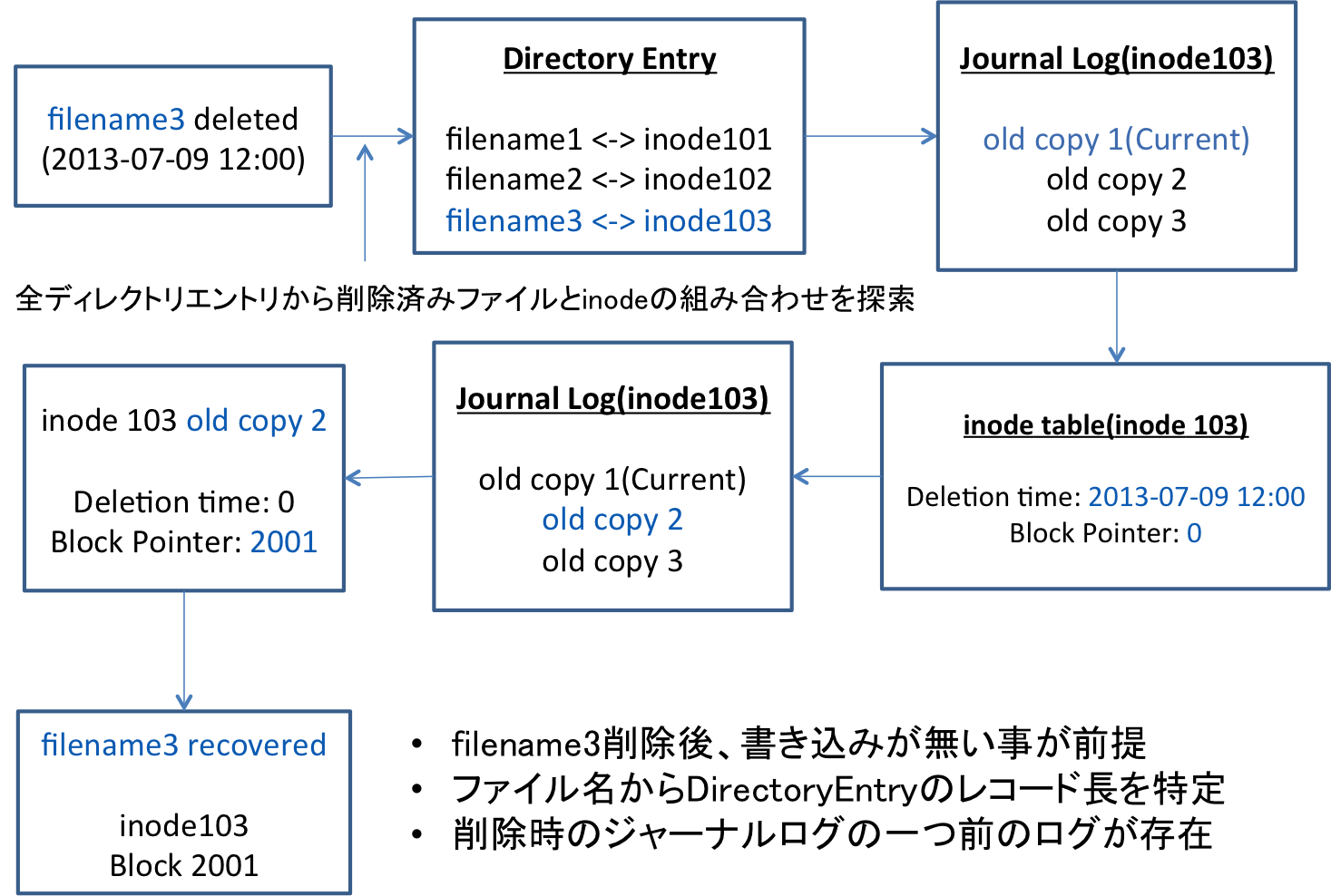
まず、あるタイミングでfilename3が削除されたとします。その場合、まずはディレクトリエントリの情報を舐めます。ディレクトリエントリは前述した通り、ファイルを削除してもその情報を0埋めせずに、一つ前のディレクトリエントリのレコード長を伸ばす事で削除対象のディレクトリエントリをルール上見えなくするといいました。
つまり、レコード長を無視して、純粋にファイル名から最適なレコード長を計算するようにしてやれば、ルール上見えなくなっていたディレクトリエントリも拾えるようになるはずです。
それによって、削除したファイル名とinodeの組み合わせを得る事ができます。
続いて、そのinode番号からジャーナルログを追いかけます。その際に、最新のジャーナルログ(old copy1)はファイルを削除したログを残しているため、Deletion Timeが0ではなく、かつ、Block Pointerが0になっているはずです。そして、そのinodeに関するジャーナルログの1つ前のログ(old copy2)をとってきます。すると、その中には削除イベントが発生する前のログ、つまりBlock Pointerに削除したデータを指し示すデータブロックのアドレスが入っているはずです。
これらによって、削除したファイルに必要なデータブロック、ファイル名が得られたため、そこから無事にファイルを復元することができそうです。
ファイル名を正しく復元したい場合の注意点
前述した方法で、ファイルデータ自体は高確率で復元することができるでしょう。しかし、ファイル名も正しく復元したいとなると、注意する点があります。それは、「削除したファイルがまだ存在していなかった時点に、同一のinodeで存在したファイルが削除されていた場合」です。
少し分かりにくいので、図で見てみましょう。
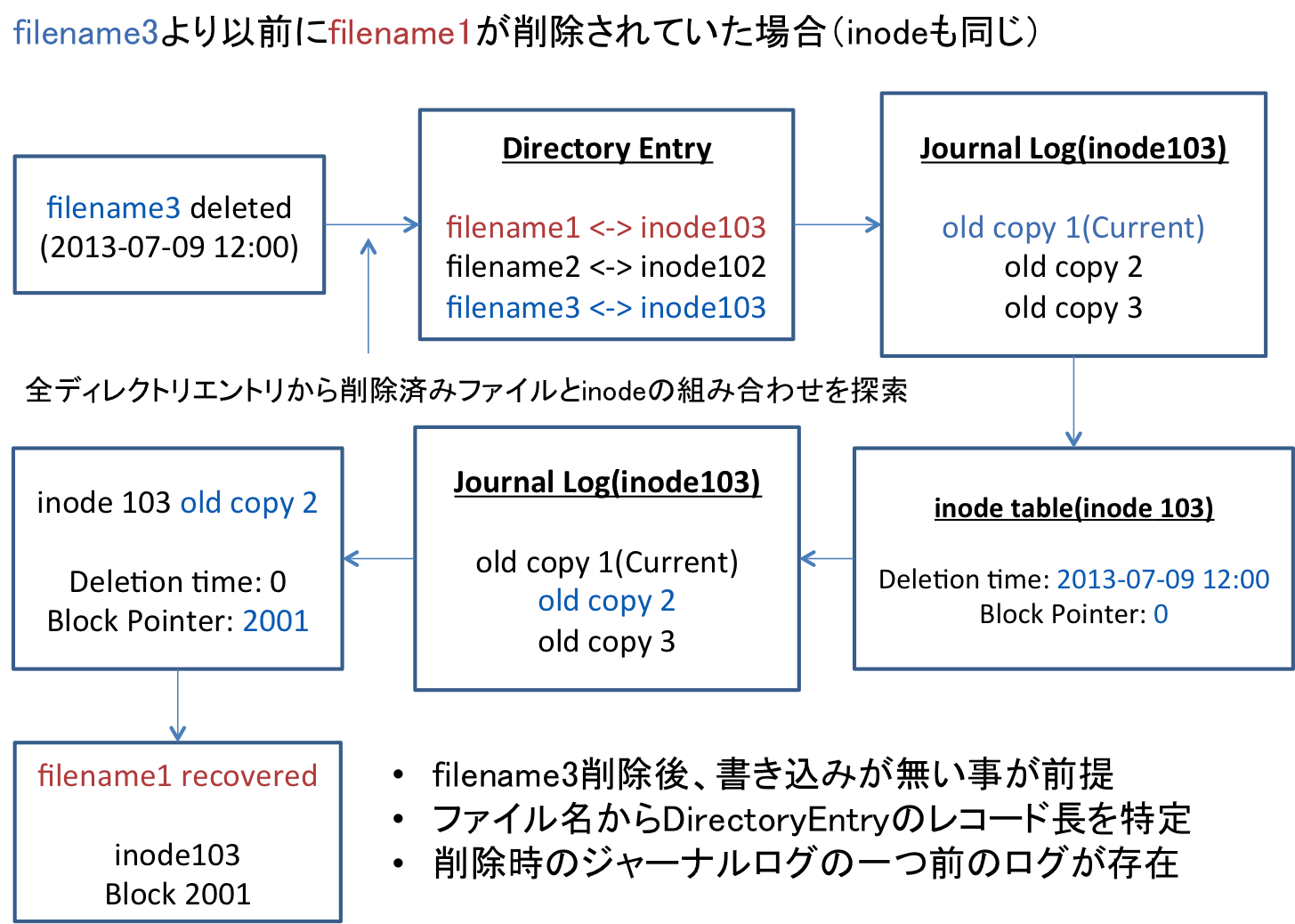
まず、filename3を削除したとします。そこで、前述した手法でディレクトリエントリを辿り削除したファイル名に紐づくinodeを見つけ出します。この状況において、「削除したファイルがまだ存在していなかった時点に、同一のinodeで存在したファイルが削除されていた場合」には、同一のinodeで違うファイル名のディレクトリエントリが複数存在してしまう場合があります。
ディレクトリエントリの仕様上、削除されたファイルの一つ前のレコード長を伸ばすため、これを繰り返しおこなう事によって、さらに以前に同一のinodeを使っていたファイル名に対応したディレクトリエントリが残っており、それを抽出してしまう可能性があるのです。
これによって、削除したファイル名とそのinodeの組みの他に、違うファイル名と同一のinodeの組み合わせを見つけてしまいます。上図の場合はそれがfilename1にあたります。これを気をつけないと、filename3でそれが指し示すデータブロックを復元したいのに、filename1でfilename3のデータを復元してしまう事もあります。
プログラムの書き方にもよりますが、先に見つけたファイル名を復元させる、といった実装をしていると、誤ったファイル名でデータを復元してしまうでしょう。そのため、削除対象のファイル名が指すinodeに対する組み合わせが、ディレクトリエントリから複数得られた場合は、復元しない、あるいは、ファイル名の判断がつかないデータ、としてしまった方が良いでしょう。
なぜなら、ディレクトリエントリから、「どちらのファイルが先に存在したファイルなのか」という時系列的な比較をすることが、ディレクトリエントリ上のデータから判断するのは難しいからです。
最後に
以上がext3ファイルシステムにおける重要な要素の、ディレクトリエントリ、inode、ジャーナリングに関する仕様と、それに基づくファイル削除・復元の方法を考えてみました。
ext3はこのようなやり方でファイルを復元できるだろうと思いますが、今後ext4やBtrfsでこの辺りをどうやったら良いのかはまだ調べられていないので、今後時間を見つけて調査していきたいと思います。
しかし、こういう処理を考えれば考える程、やっぱり一番幸せなのは、ある意味「削除したら復元はできない」という事なのかもしれませんね。
もし、mod_mrubyも含めてこういうOSの基本的な事からWebサーバ、そしてインターネットに関する研究をしたい人(特に学生)がいたら、いつでも研究室でお待ちしております。是非一緒にこういう楽しい研究しましょう!