
※春に行った京都の玄武岩
さて、久々の研究報告です。
NECさんの開発している変化点検出エンジン「ChangeFinder」を、プログラムで実装してみました。
「ChangeFinder」は、これまでの従来の手法による変化点検出にかかる計算コストを大幅に削減した独自のアルゴリズムによって開発されています。
データマイニングの観点から、外れ値と変化点を区別して、変化点を検出することに成功しています。
このように、変化点と外れ値は同一のアルゴリズム内で扱うのは難しいとされてきた中で、計算量を削減した上で同一に扱えるというのは、かなり画期的な手法です。
それでは、実験的にデータを発生させたりすることで、適当な時系列データを作成し、どの程度の精度と計算コストで検出できるかを実験してみました。
結果からいうと、すばらしいです!
では、簡単に数値シミュレーション結果を示していきます。
■画像をクリックして拡大表示できます。
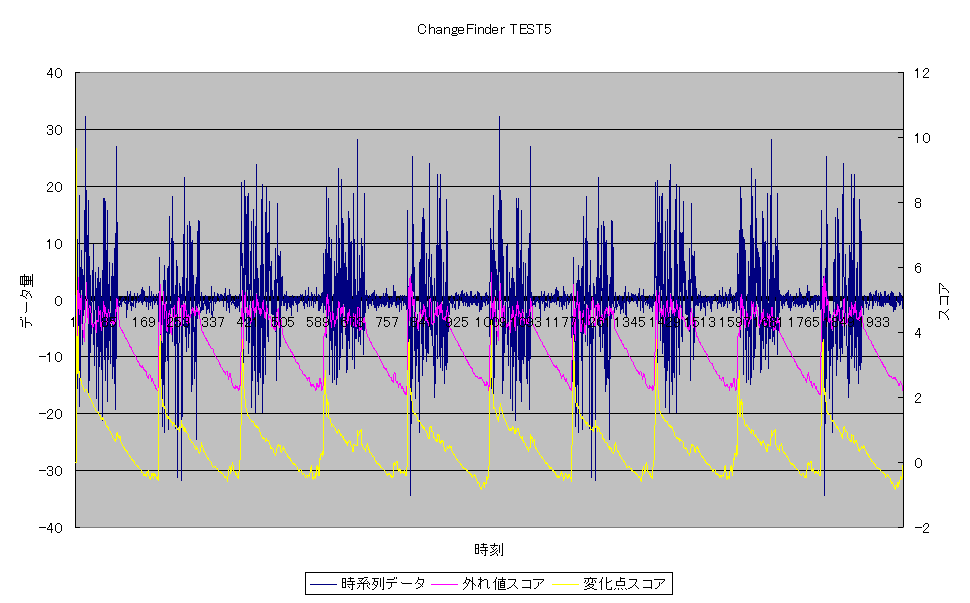
※ホワイトノイズの倍数変化での時系列データにChangeFinderを適用

図1:期待値0、分散1のガウス分布に従うノイズを用いてARモデルによりデータ作成
これは、10000個の時系列データをある規則によって発生させ、予め1000データごとに、仮想的に変化点を作成し、それを「ChangeFinder」でシミュレーションしてみました。
「ChangeFinder」は、2段階の学習を行うことで、最終結果を得ています。
1段階で得られたスコアが、ピンクのグラフで、そのデータを元に再度学習して得られたスコアが、黄色の変化点スコアとなります。
このように、時系列データに対して、最終的な結果である黄色の変化点スコアが、変化点の時点で高いスコアをはじきだしていることがわかります。
この計算は1秒かからない程度の計算でした。
次に、データ10万個で試してみました。
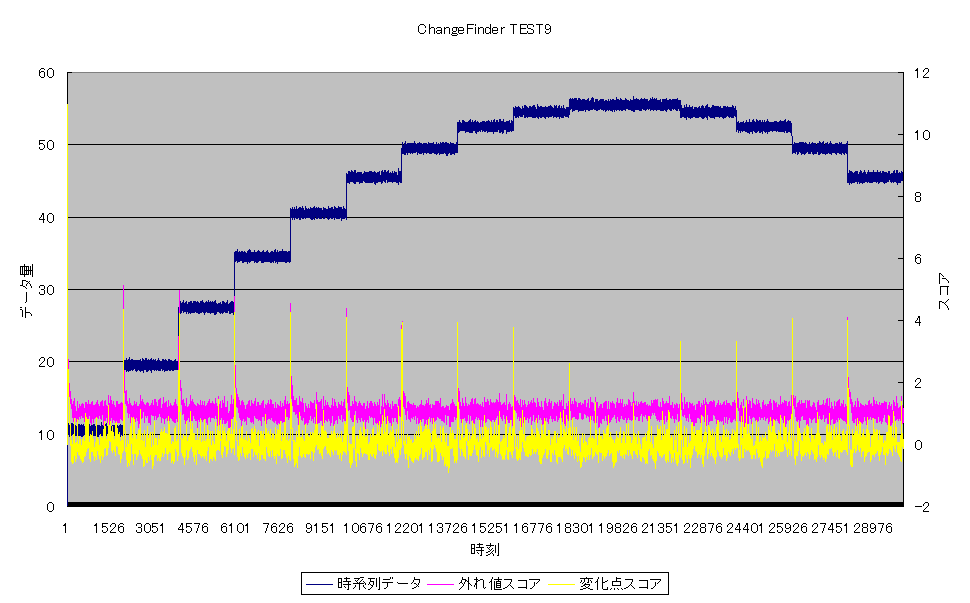
図2:図1と同じような手法で、ノイズや変化点の計算方法を少し変更させてデータ発生
これも、計算時間はPCにもよりますが、2秒程度でした。
この時系列データでも、黄色の変化点スコアは、変化量によって、その変化を反映したようなスコアを算出しています。
時系列データを読むごとに、少しずつそのデータの特徴を学習していくのですが、後半になっても、十分変化に対応できていることがわかります。
これは、忘却型学習アルゴリズムというものを採用していて、統計的に見たときに、評価するデータに時間的に近ければ近いほど、統計量の影響を大きくし、過去のデータであればあるほど、影響を少なくするようにしているからです。
このため、変化の特徴を、学習後も高い精度でとらえることができています。
それでは、最後に株価の変動のような時系列データに適用してみます。
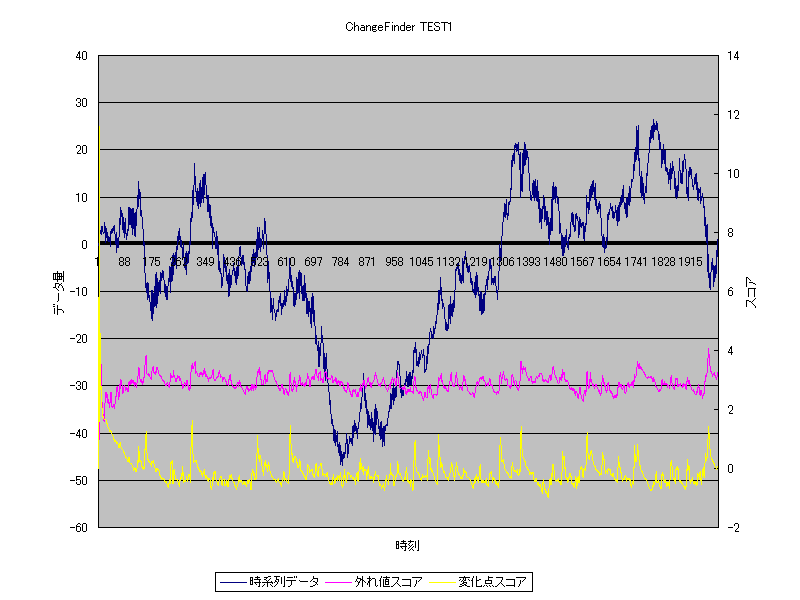
図3:株価の変動の時系列データ
これも結果をみると、急激な変化は高いスコアで検出することができています。
また、真ん中あたりのような、ゆるやかな変化に対しては、スコアは低い値になっています。
このように、いわゆる非定常なデータに対しても、高い精度で変化点スコアを算出することができており、計算量と過去の統計量による特徴の検出の難しさ、を克服できているのではないかと考えられます。
最終的には、この変化点検出をネットワークセキュリティに応用したいと考えているので、扱うデータ自体を工夫するか、この手法を改良、例えば多次元のデータに対応させ、それらの相関から、よりネットワークセキュリティにおいて、重要なインシデントを分析することができるのではないか、と考えています。